
WordPress Managed Hosting
An in-house, bespoke multi-tenant WordPress hosting platform on Kubernetes. Every site is a label-scoped set of Kubernetes resources; one typed TypeScript CLI turns a code-defined site database into manifests, DNS, backups, and billing.
Stack
Problem
Running WordPress for a handful of agency clients may sound simple but is deceivingly complex for non-trivial operational requirements. Every site needs its own isolated database and credentials, an SFTP endpoint for the client’s developers, a working URL with SSL that survives domain changes, backups of both the filesystem and the database, and a way to restore, migrate, suspend, or archive on demand.
One VM per site degenerates into snowflakes. Every box drifts, every certificate renewal is manual, every backup script is subtly different, and past a few dozen sites nobody knows what is running where. One shared WordPress Multisite install goes the other way and trades isolation for blast radius: a single plugin update can take down every tenant at once.
WPMH is the third option. Each site is a unit of deployment on Kubernetes, defined once in code, with tooling generating everything else.
Approach
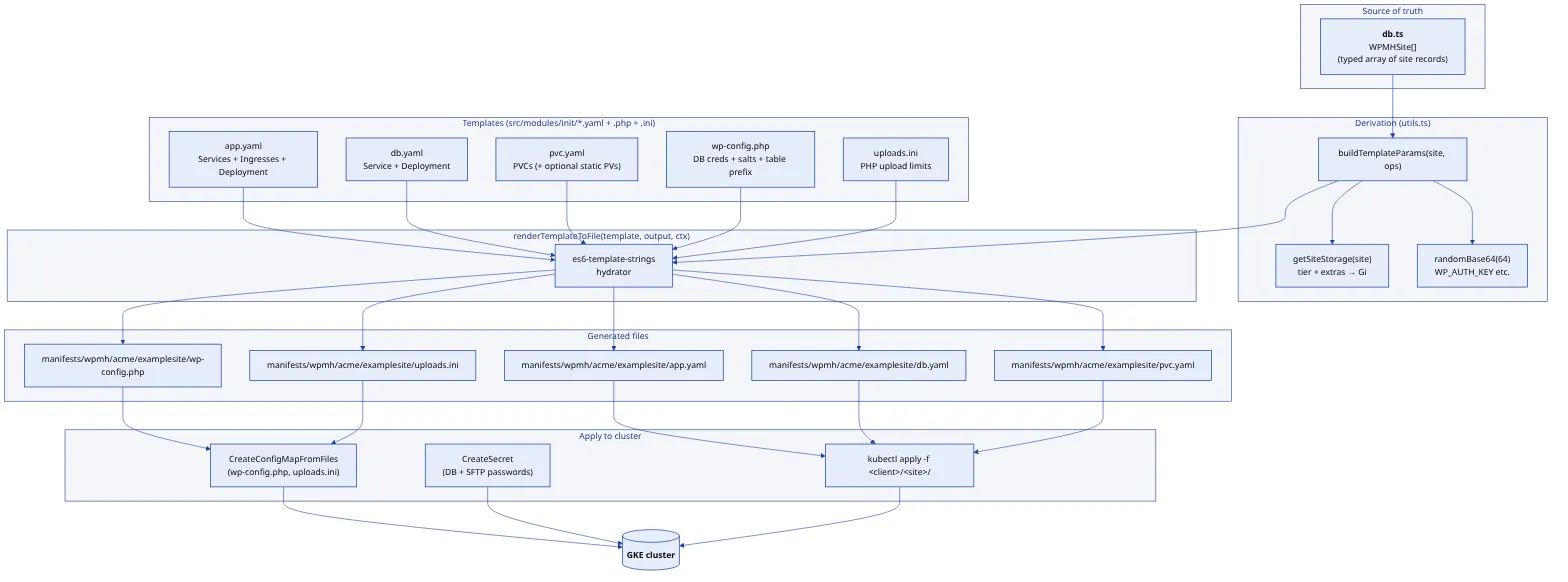
One typed TypeScript array is the single source of truth. A site is a record: client, domains, PHP and WordPress versions, dates, storage tier. Everything else is derived from it: Kubernetes manifests, Terraform variables, DNS records, snapshot schedules, the monthly bill. Reviewing a one-line change to that file is enough to know exactly what infrastructure will move.
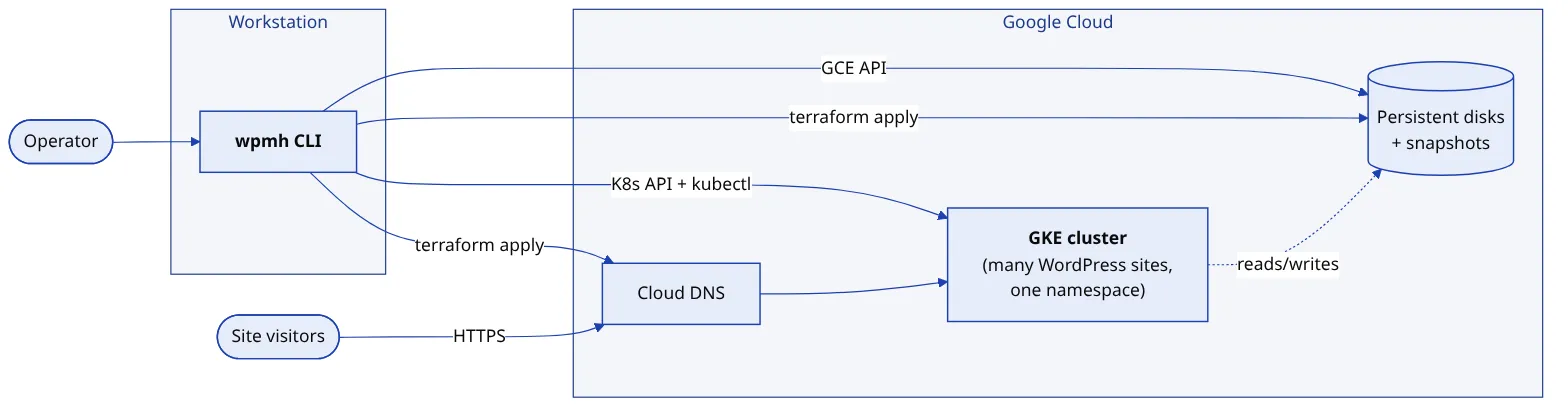
Every site has the same shape; only the labels and the storage size change. A WordPress pod runs the unmodified upstream image alongside a WP-CLI sidecar and an SFTP sidecar, all three sharing one volume so an uploaded plugin is visible everywhere at once. A MariaDB pod sits behind it, reachable only on port 3306 and only from its own site’s app pod. One Ingress per domain carries its own automatically-renewed certificate.
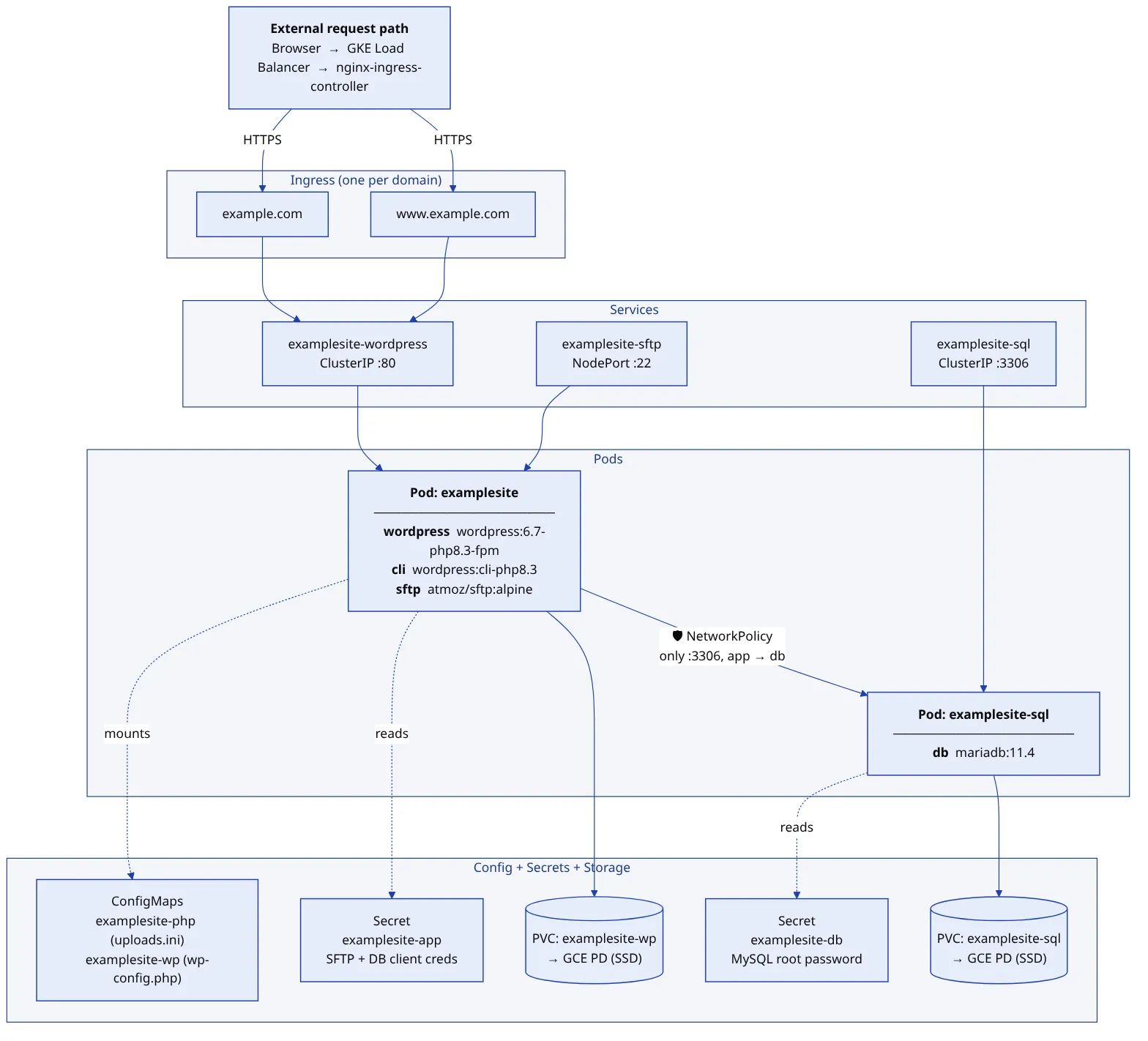
There are no per-tenant clusters or namespaces. The whole fleet lives in one namespace, isolated by a consistent label schema of app, client, role, env, and tier. “Everything for one site,” “every WordPress pod in the fleet,” and “all production sites for one client” are the same primitive: a label selector. NetworkPolicies, not namespace boundaries, enforce that a compromised pod cannot reach another site’s database.
Manifests are generated by ES6 template strings, not Helm charts. There is no template DSL to learn and no values.yaml indirection: a JavaScript function produces YAML, debuggable with cat and diff. The rendered files are committed, so drift between what should be running and what was last rendered shows up in git status.
A site is never truly deleted. It can be suspended (snapshots taken, Kubernetes resources torn down, the persistent disks retained), which parks it cheaply and brings it back in seconds. Or it can be archived: snapshots retained, disks released, billing stopped. Unarchiving rebuilds a fully torn-down site from its snapshots, including booting MariaDB in recovery mode to reset a root password that no longer exists anywhere else. Every destructive operation takes a snapshot before it starts.
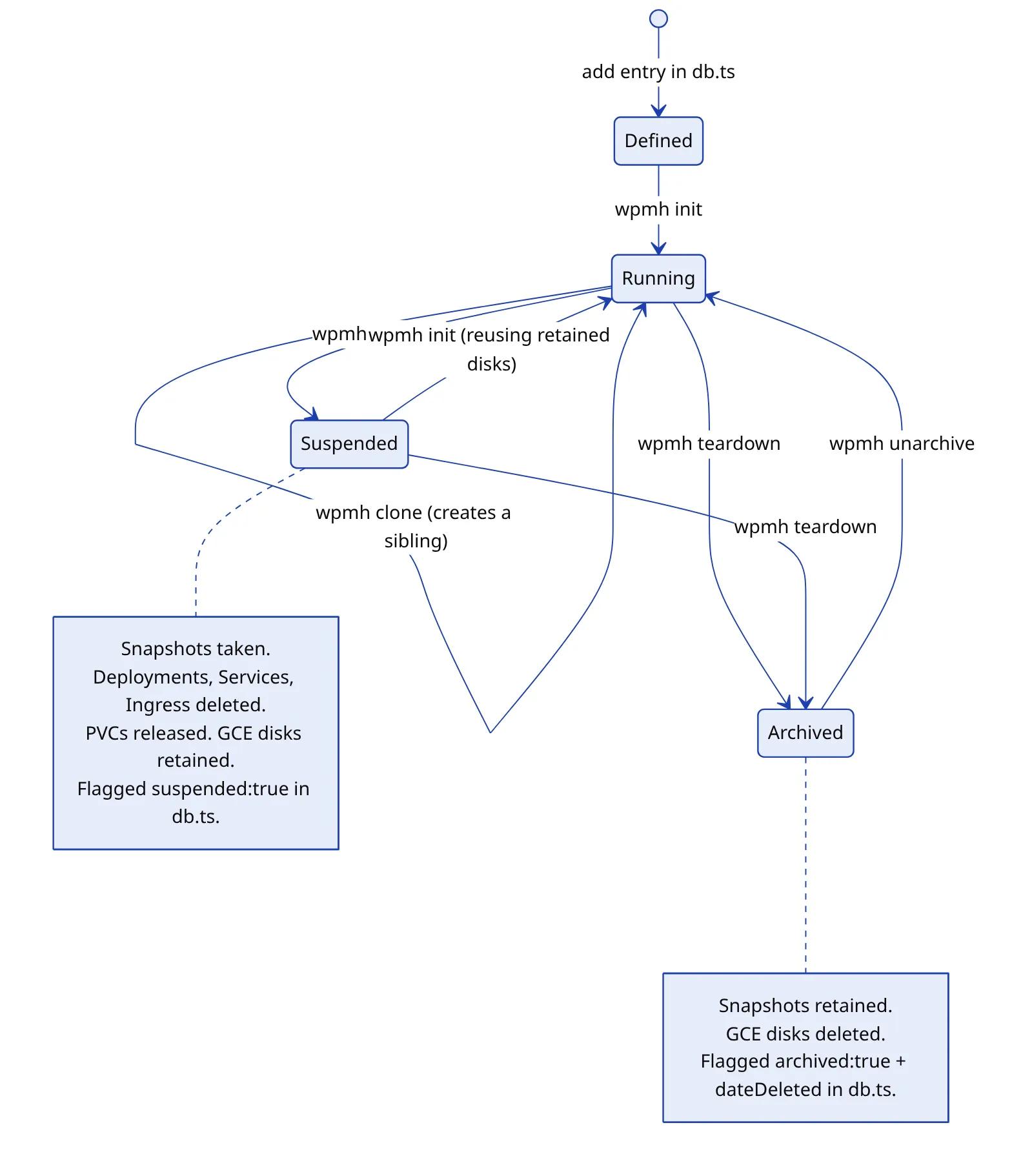
Durability is snapshot-based by design. A Terraform-managed policy snapshots every disk daily; manual snapshots are taken before anything destructive; on-demand WP-CLI exports deliver a client their own data. Disk snapshots are atomic at the block level, incremental, and restored as a GCP-internal operation, so a recovery costs the time to create a disk, not the time to download one. The tradeoff is accepted explicitly: snapshots are GCP-specific, and moving clouds would mean adding a dump-and-restore path.
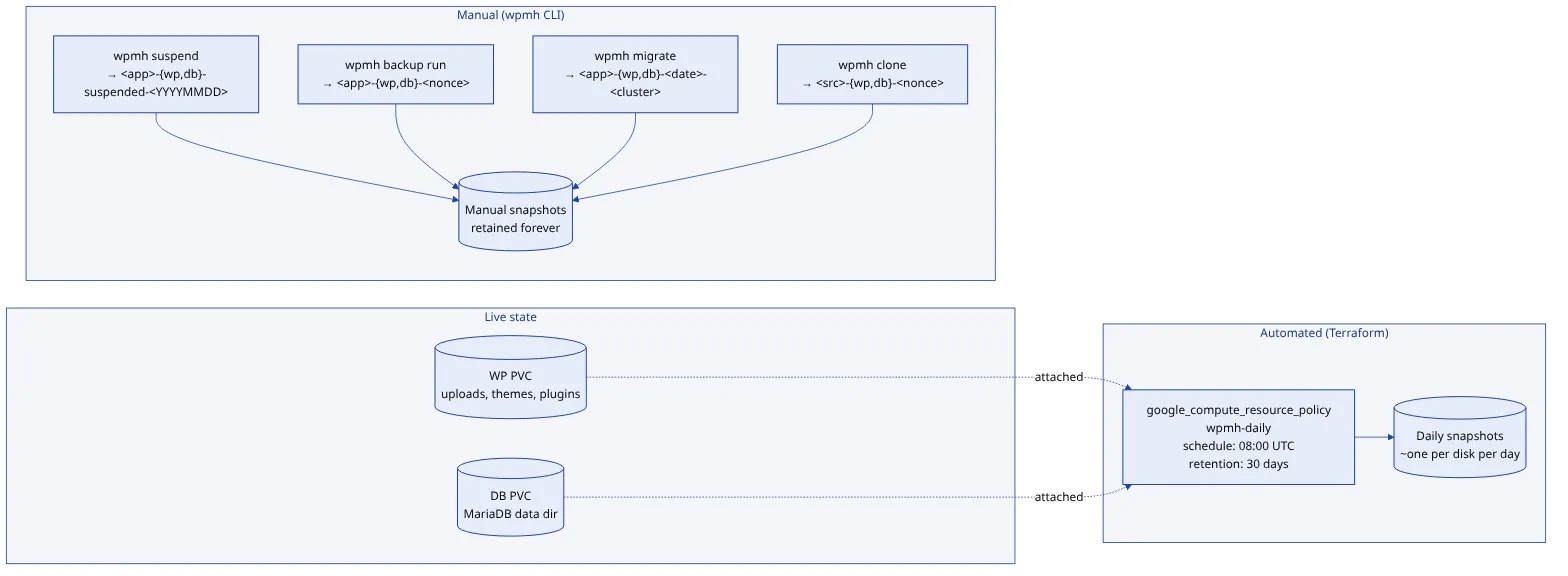
The control plane is one binary an operator runs from a workstation. No UI, no API server, no CI/CD pipeline, no continuous reconciler. Production safety comes from human review of a typed file, not from pipeline gates. Helm, Kustomize, and ArgoCD were each considered and left out; at this scale they add operational surface without paying it back.
Outcome
Dozens of sites for a handful of agency clients, continuously in production since 2019, provisioned without manual steps and snapshot-backed every day. Adding a site is one command. Rolling one back to a known-good point is another. A storage-tier change is one line in the site database, and the next billing cycle reflects it without anyone touching an invoice.
Because everything derives from one typed source, the operations that are normally a hosting platform’s most dangerous (restore, migrate, suspend, archive) became reliable and routine.